
Automating systematic reviews while maintaining methodological rigor
The Systematic Review Bottleneck
Systematic reviews are the gold standard of evidence synthesis—but they're painfully slow. A typical review requires screening thousands of abstracts, extracting data from hundreds of full texts, and calculating pooled effects across dozens of included studies [1].
The numbers are sobering: a Cochrane review takes an average of 67 weeks to complete, with some exceeding 3 years [2]. During this time, new studies publish, clinical guidelines remain uncertain, and policy decisions wait.
MetaSynth: Evidence Synthesis at Scale
MetaSynth automates the systematic review pipeline end-to-end—from initial literature search to publication-ready forest plots—while maintaining the sensitivity and rigor that evidence synthesis demands.
Intelligent Screening
The system learns your inclusion/exclusion criteria from a small training set (50-100 abstracts), then applies them across thousands of records:
- >95% sensitivity: Captures virtually all relevant studies, matching or exceeding human performance [3]
- 70-80% specificity: Dramatically reduces screening burden while flagging borderline cases for human review
- Transparent decisions: Every exclusion includes the reasoning, enabling rapid verification
What takes a two-person team 4-6 weeks of abstract screening becomes a 2-hour process with targeted human review.
Automated Data Extraction
From included full texts, MetaSynth extracts:
- Study characteristics: Design, population, setting, intervention details
- Outcome data: Means, SDs, effect sizes, confidence intervals
- Risk of bias indicators: Randomization, blinding, attrition, selective reporting
- Moderator variables: Subgroup characteristics for meta-regression
Extracted data populates standardized templates aligned with Cochrane and PRISMA guidelines [4].
Meta-Analytic Engine
With extracted data, the system calculates pooled effects using appropriate models:
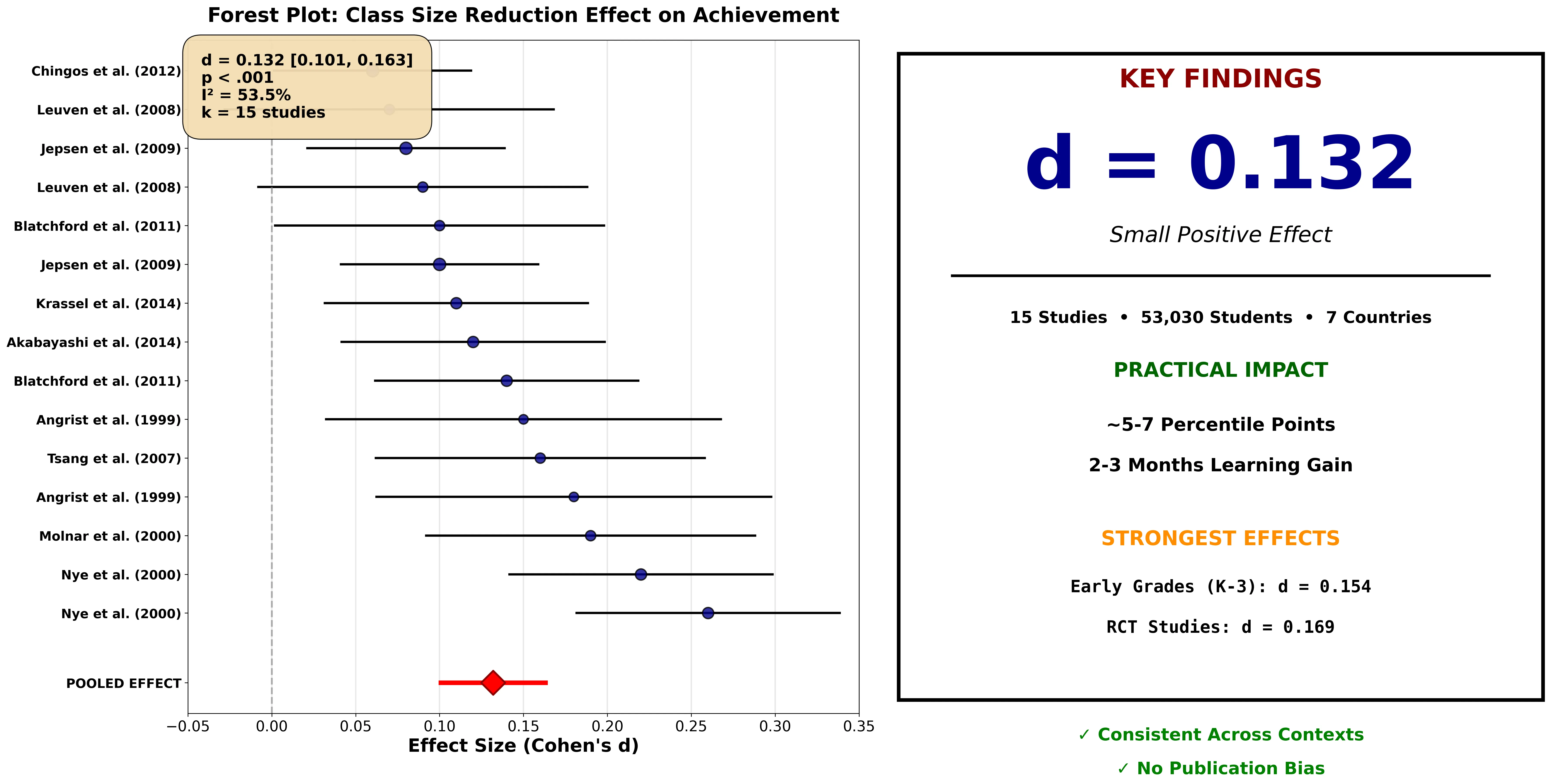 Figure 1: MetaSynth-generated forest plot showing class size reduction effects on achievement (d = 0.132, 95% CI [0.101, 0.163], k = 15 studies, N = 53,030). The analysis identifies moderators (early grades, RCT designs) and confirms no publication bias.
Figure 1: MetaSynth-generated forest plot showing class size reduction effects on achievement (d = 0.132, 95% CI [0.101, 0.163], k = 15 studies, N = 53,030). The analysis identifies moderators (early grades, RCT designs) and confirms no publication bias.
Statistical capabilities:
- Random-effects models: Accounting for between-study heterogeneity
- Heterogeneity assessment: Q-statistic, I-squared, prediction intervals
- Subgroup analysis: Categorical moderator comparisons
- Meta-regression: Continuous moderator effects
- Publication bias: Funnel plots, Egger's test, trim-and-fill adjustment
- Sensitivity analysis: Leave-one-out, influence diagnostics
Publication-Ready Outputs
MetaSynth generates:
- Forest plots with study labels, effect sizes, and confidence intervals
- PRISMA flow diagrams documenting the screening process
- Summary of findings tables for guideline development
- Risk of bias visualizations (traffic light plots, summary graphs)
- Exportable data for verification and re-analysis
Maintaining Rigor
Automation raises legitimate concerns about transparency and validity [5]. MetaSynth addresses these through:
Human-in-the-loop design: Borderline screening decisions and low-confidence extractions are flagged for expert review
Full audit trails: Every automated decision is logged and traceable
Sensitivity thresholds: Conservative defaults prioritize recall over precision—missing relevant studies is worse than including irrelevant ones
Reproducibility: All parameters, seeds, and decision rules are documented for replication
Real-World Impact
| Traditional Review | MetaSynth-Assisted |
|---|---|
| 12-18 months | 2-4 weeks |
| 2-3 full-time researchers | 1 researcher + verification |
| 2,000 abstracts screened manually | 10,000+ abstracts screened |
| Data extraction: 40+ hours | Data extraction: 4 hours + review |
Applications
Automated evidence synthesis has applications across research domains where systematic reviews inform decisions:
Clinical medicine: Informing treatment guidelines and health technology assessments where timely evidence synthesis affects patient outcomes
Education research: Aggregating intervention studies across heterogeneous populations and settings
Social Policy: Synthesizing program evaluations to guide resource allocation
Research Planning: Quantifying existing effect sizes and identifying gaps to inform study design and power calculations
The Future of Evidence Synthesis
The gap between the demand for synthesized evidence and the field's capacity to produce it continues to widen. Thousands of clinical and policy questions lack systematic reviews. Automation does not replace the methodological expertise underlying rigorous evidence synthesis. Rather, it addresses the mechanical bottlenecks - screening, extraction, and computation - that consume the majority of review time. The result is a redistribution of effort: less time on repetitive tasks, more time on methodological decisions, quality assessment, and interpretation that require human judgment.
References
[1] Borah R, et al. Analysis of the time and workers needed to conduct systematic reviews. BMJ Open. 2017;7(2):e012545.
[2] Beller EM, et al. Making progress with the automation of systematic reviews. Systematic Reviews. 2018;7:77.
[3] O'Mara-Eves A, et al. Using text mining for study identification in systematic reviews. Systematic Reviews. 2015;4:5.
[4] Page MJ, et al. The PRISMA 2020 statement: an updated guideline for reporting systematic reviews. BMJ. 2021;372:n71.
[5] Marshall IJ, Wallace BC. Toward systematic review automation: a practical guide to using machine learning tools. Systematic Reviews. 2019;8:163.